En trois mois, ma facture Cursor a quadruplé.
Pas parce que les tarifs ont augmenté. Juste parce que je consomme beaucoup plus.
Ces deux dernières années, l’abonnement de base à 20 $ m’a toujours suffi.
Mais depuis Claude Opus 4.6, ça a changé :
- En février, je suis passé sur l’abonnement à 60 $/mois, et j’ai largement débordé avec 84 $ d’usage supplémentaire.
- En mars, je passe au palier supérieur à 200 $/mois, et ça ne suffit toujours pas. 210 $ de surplus au compteur en fin de mois.
- En avril, j’ouvre un deuxième compte à 200 $ pour avoir encore plus de tokens. Même là je dépasse encore. Facture finale en avril : 580 $.

Est-ce que ça valait le coup ? 100 % oui. Aucun doute.
Mais là n’est pas la question : Quand est-ce que cette augmentation incontrôlable va s’arrêter ?
Alors je me suis arrêté.
Pas pour résilier. Pour comprendre où partait cet argent.
Pourquoi certains prompts consomment 50 000 tokens, alors que d’autres en consomment plusieurs millions ?
Quelle différence entre les tokens “Input”, “Output”, “Cache Read”, “Cache Write” ?
Si je voulais réduire ma facture, il fallait que je comprenne.
Dans cet article, on va voir comment ça marche :
- Comprendre pourquoi les tokens n’ont pas tous le même prix
- Le mécanisme clé : On repaie les mêmes tokens plusieurs fois sur un même prompt
- Les changements dans ma pratique pour réduire ma consommation de tokens
- Aller plus loin : Auditer sa baseline
1. Comprendre pourquoi les tokens n’ont pas tous le même prix
À chaque fois qu’on envoie un prompt à un LLM, on paie deux types de tokens :
- Les tokens d’entrée (Input) : Ce qu’on envoie au modèle.
- Les tokens de sortie (Output) : Ce que le modèle nous envoie.
Ces deux types de tokens ont une tarification différente. En général, les tarifs affichés sont pour 1 million de tokens.
Par exemple pour l’API de Claude 4.7 :
- Input Tokens : 5 $ pour 1 million de tokens
- Output Tokens : 25 $ pour 1 million de tokens
Chaque API va avoir des tarifs différents, selon le provider, et selon le modèle.
Dans Cursor, l’input envoie non seulement ce qu’on tape dans le prompt, mais aussi :
- le prompt system de Cursor (les instructions de base de l’agent)
- les descriptions des rules, skills, MCPs, et plugins
- les fichiers qu’on attache, ou que l’agent va lire de manière autonome
- les résultats des appels aux tools que l’agent déclenche
Et l’output, c’est tout ce que le modèle nous renvoie :
- le texte affiché dans le chat
- les blocs de code rajoutés dans les fichiers
- les arguments des appels aux tools
- le « raisonnement » qu’il déroule en interne (pour les modèles de type thinking)
Jusque là, c’est simple à comprendre.
Le mécanisme caché : Cache Write et Cache Read
Il existe deux autres catégories un peu plus complexes à comprendre.
Les fournisseurs comme Anthropic ou OpenAI proposent un mécanisme de cache de prompts. Quand vous envoyez un long contexte au modèle, l’API peut le stocker temporairement (5 minutes ou 1 heure chez Anthropic) pour que les requêtes suivantes n’aient pas à le retraiter de zéro.
Concrètement :
- Cache Write : la première fois qu’un bloc de contexte est envoyé, il est traité et mis en cache. C’est un peu plus cher qu’un input normal (x1,25 ou x2 selon la durée de stockage), mais ça ne se paie qu’une fois.
- Cache Read : à chaque appel suivant qui réutilise ce bloc, il n’est pas retraité, juste relu depuis le cache. Et là, le tarif tombe à 10 à 25% du prix d’un input, selon le fournisseur.
En gros : Grâce à ces systèmes de cache, on paie plein pot une fois, puis le prix est fortement réduit pour tous les usages suivants.
En pratique, c’est là que tout se joue.
Les volumes de tokens
Si je regarde mon usage de tokens de ces derniers jours :
| Catégorie | Volume | % du total |
|---|---|---|
| Input (avec Cache Write) | 9,6 M | 7 % |
| Input (sans Cache Write) | 8,5 M | 6 % |
| Cache Read | 111 M | 85 % |
| Output | 1,3 M | 1 % |
Le constat est sans appel : les Cache Reads dominent largement le volume.
Même à 10 % du tarif, leur poids sur la facture finit par dépasser tout le reste réuni.
Suite à ce constat, il me restait une simple question :
Comment une seule requête peut-elle accumuler des millions de tokens ?
La réponse tient dans un concept que je n’avais pas vraiment intégré : le “tour”.
2. Le mécanisme clé : on repaie les mêmes tokens à chaque tour
On a tendance à penser que “un prompt” = une requête API.
Quand j’ouvre le chat de Cursor, je tape un prompt, et l’agent me répond.
En arrière-plan, Cursor prend mon prompt, l’assemble avec son prompt system et autres bricoles, et l’envoie vers l’API de Claude.
Un seul prompt.
Mais potentiellement plusieurs échanges avec le modèle via l’API.
Un prompt = plusieurs « tours »
Un tour (en anglais : turn), c’est un aller-retour avec l’API du modèle.
Tant que l’agent peut répondre directement, ça reste un seul tour.
Mais dès qu’il a besoin d’aller chercher une information dans le monde extérieur :
- lire un fichier,
- lancer une commande,
- faire un
grep,
il faut un nouveau tour.
Le déroulé est toujours le même :
- Le modèle émet une réponse qui inclut « je veux utiliser tel outil avec ces arguments » (un tool call)
- Cursor exécute le tool localement (lecture de fichier, commande shell, etc.)
- Le résultat est renvoyé au modèle dans un nouvel appel à l’API, pour qu’il puisse continuer.
Entre les étapes 1 et 3, il y a un nouvel appel API. Facturé.
Chaque tour renvoie tout
C’est ici que ça devient crucial.
Quand je parle à un être humain, je n’ai pas besoin de lui répéter la conversation entière à chaque intervention de ma part. Il se souvient des échanges précédents.
Un agent IA ne fonctionne pas comme ça. Il n’a pas de mémoire. On lui donne juste un contexte en entrée, et il prédit la suite.
Même les systèmes de mémoire des fournisseurs d’IA ne sont que des artifices. Ce n’est qu’un fichier texte qui est maintenu et ré-injecté à chaque fois dans le contexte.
De la même manière, quand le modèle reçoit le résultat d’un tool pour continuer, l’API ne reçoit pas seulement le nouveau résultat. Elle reçoit l’intégralité de l’historique. Pas juste ce qui a changé depuis le dernier tour. Tout.
On va voir un exemple concret.
Tour 1
J’écris le prompt suivant dans une nouvelle conversation :
« Commit le correctif que j’ai implémenté ».
En output, l’agent me répond :
« Je vérifie l’état du dépôt et le diff pour préparer le commit du correctif. »
Et il déclenche 4 tool calls :
- Lecture de la rule git-standards.mdc
- Commande lancée :
git status - Commande lancée :
git diff && git diff --staged - Commande lancée :
git log -5 --oneline
Pour ce tour, je suis facturé en input du prompt que j’ai écrit et du prompt system de Cursor.
Et en output, je suis facturé de la réponse écrite de l’agent, ainsi que de l’écriture des tool calls.
Tour 2
L’agent n’a pas terminé, donc il continue. Grâce aux tool calls, il est allé chercher le contexte nécessaire pour faire le commit demandé.
Nouvelle requête à l’API, mais cette fois-ci l’input est beaucoup plus complet : mon prompt, le prompt system, le texte de réponse de l’agent, et le contenu les 4 tool calls.
L’agent me répond :
« Le correctif gère les corps de post
NAdans l’aperçu des cartes. Je ne commite que ce fichier, pas le dossierscripts/non suivi. »
Et il déclenche un nouveau tool call :
- Commande lancée :
git add xxx && git commit -m "yyy" && git status
Fin du tour.
Tour 3
L’agent doit terminer sa réponse et m’informer de ce qui a été fait.
Encore une nouvelle requête à l’API avec : mon prompt initial, le prompt system, la 1ère réponse de l’agent, le contenu des 4 premiers tool calls, la 2e réponse de l’agent, et la sortie du dernier tool call.
Et l’agent écrit sa réponse finale :
« Commit créé sur
dev/charles. Blablabla. »
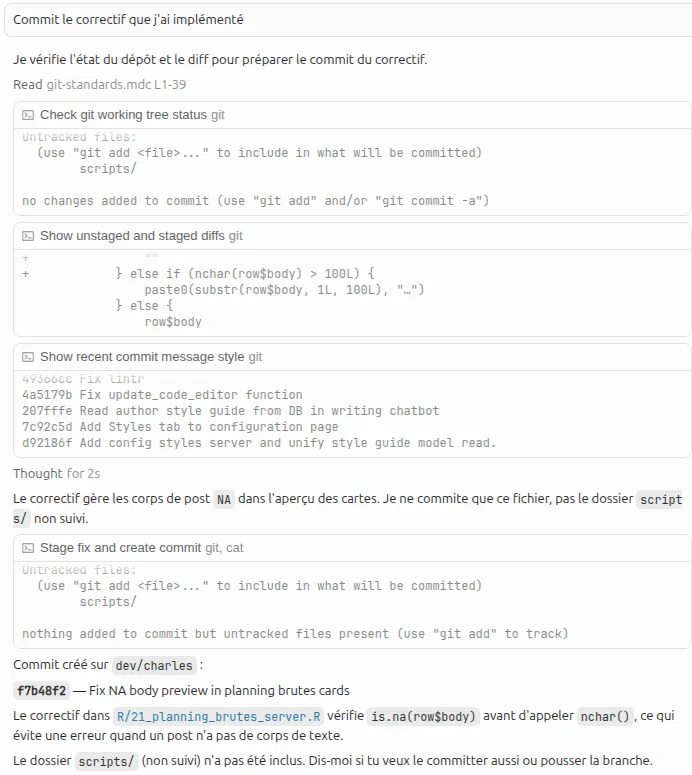
1 prompt = 3 tours
Au final, ce simple prompt aura provoqué trois appels API. À chaque appel API, le contexte est de plus en plus fourni puisqu’il contient tout ce qui s’est passé avant.
Dans cet exemple, j’ai démarré une nouvelle conversation. Mais on comprend très vite que plus une conversation dure dans le temps, plus chaque prompt va consommer un nombre important de tokens.
D’après Cursor, ma conversation contient 18 200 tokens de contexte.
Pourtant, j’ai été facturé de 52 485 tokens.

Pourquoi ? Parce qu’il y a eu 3 tours, donc 3 requêtes API.
18200 x 3 = 54600 donc on retombe sur nos pieds. Pas exactement parce que chaque tour est un peu différent des autres, et les tokens facturés sont découpés entre l’input et l’output, mais l’ordre de grandeur est là.
Parallèle vs série
Ce mécanisme a une conséquence directe sur la façon dont l’agent travaille.
Un bon agent batche les tool calls indépendants dans un même tour.
S’il doit lire 5 fichiers qui n’ont pas de dépendance entre eux, il les demande tous d’un coup dans son tour de réponse : « lis-moi A, B, C, D et E ».
Cursor exécute les 5 lectures en parallèle, et au tour suivant l’agent reçoit les 5 résultats d’un seul bloc pour continuer.
5 tool calls en parallèle = 1 tour supplémentaire.
Un agent moins habile, lui, les enchaîne en série. Il demande A. Il attend le résultat. Il décide alors de lire B. Il attend. Puis C. Et ainsi de suite.
À chaque nouvelle lecture, c’est un tour de plus, donc une nouvelle requête API, avec tout l’historique accumulé jusque-là rejoué dans l’input.
5 tool calls en série = 5 tours supplémentaires.
Pour le même résultat final, la facture explose.
Pourquoi deux requêtes peuvent coûter du simple au double
Avec ce mécanisme en tête, l’écart entre un prompt à 50 000 tokens et un autre à plusieurs millions n’a plus rien de mystérieux. Tout dépend de deux choses :
- combien de tours l’agent a dû faire pour me répondre,
- et à quelle vitesse le contexte grossit à chaque tour.
Un prompt « léger », c’est quelques tours bien batchés, sur un contexte qui reste petit. Un prompt « lourd », c’est un agent forcé d’enchaîner ses lectures en série, où chaque nouveau tour traîne un historique de plus en plus volumineux.
Une fois qu’on a ça en tête, on regarde sa consommation autrement. Et surtout : on commence à voir où on peut agir.
3. Les changements dans ma pratique pour réduire ma consommation de tokens
Les changements que je présente ci-dessous m’ont permis de passer d’une facture de 580 $ à “seulement” 400 $. Ça veut dire que mes 2 comptes me suffisent à présent, sans avoir à utiliser de capacité supplémentaire.
Ça reste élevé, mais ça représente tout de même une diminution d’environ 30 %, ce qui est conséquent considérant que les mois précédents étaient systématiquement en augmentation.
Souvent repartir d’une nouvelle conversation
C’est de loin le levier le plus impactant.
En début d’année, j’ai eu des moments où je consommais 25 % de mon utilisation totale en une seule journée. Je ne comprenais pas.
Aujourd’hui la réponse est très claire :
- J’utilisais “Opus 4.6” en mode MAX. Le mode MAX permet d’agrandir la fenêtre de contexte de 200k à 1 million de tokens maximum.
- Et je prolongeais les conversations beaucoup trop longtemps.
Les résultats étaient bons. L’agent avait tout le contexte dont il avait besoin.
Mais si vous avez été attentifs à la section précédente, vous comprenez bien que c’était la recette parfaite pour consommer des tokens par millions.
À présent, je recommence une nouvelle conversation dès que j’en ai l’opportunité.
Exemple concret : Je ne sais pas pourquoi, mais les agents IA ont tendance à oublier les accents ou à les remplacer par le code Unicode. Il écrit \u00e0 au lieu de à.
Avant : Je rajoutais un prompt dans la conversation pour lui dire d’arrêter de massacrer les accents.
Après : Je crée une nouvelle conversation pour lui dire la même chose. Ça ne sert à rien d’avoir le contexte entier de la conversation pour cette tâche bête et méchante.
Potentiellement des millions de tokens d’économisés sur une tâche ultra simple.
Attention : Temps de réflexion ≠ coût du prompt. On va naturellement se dire que plus un agent met de temps à répondre, plus le prompt est difficile, et donc plus ça va coûter cher.
Pas du tout.
Dans l’exemple précédent, le prompt dans la nouvelle conversation est plus long : L’agent part de zéro. Il doit faire une recherche de tous les caractères \uxxx, puis les remplacer.
Alors que dans la conversation courante, c’est bien plus rapide : L’agent sait précisément où sont les occurrences puisque c’est lui qui vient de les écrire. Elles sont dans son contexte.
Malgré tout, la nouvelle conversation est plus économe. Le contexte va être largement plus condensé, donc moins de tokens consommés.
Un agent planificateur, pour les gouverner tous
J’utilise beaucoup la fonction de planification des agents sur Cursor. Le plan me permet d’affiner mon besoin, anticiper les complexités, et m’assurer que l’agent IA ne va pas faire n’importe quoi.
Avant : Je demandais à l’agent de faire un plan. Puis d’exécuter sur ce plan. Puis d’itérer là où il a fait n’importe quoi.
Après :
- Je demande à un agent de faire un plan. Je raffine le plan.
- Pour chaque tâche du plan, je demande à le déléguer à un nouvel agent (fonction Build in New Agent)
- Le nouvel agent démarre une nouvelle conversation.
L’avantage, c’est que chaque sous-agent dispose précisément du contexte dont il a besoin : le plan.
Ça rejoint le point précédent. On est dans une nouvelle conversation, avec un contexte limité mais de qualité.
Choisir le bon modèle pour la bonne tâche
Tous les modèles n’ont pas le même coût.
Avec Cursor, tous les modèles ne sont même pas facturés sur la même ligne. Un abonnement donne deux types d’usage :
- Les APIs externes (Claude, Codex, etc.)
- Le modèle de Cursor : Composer
Dans mes abonnements, c’est surtout l’usage des APIs externes que je maximise. Mon utilisation de Composer reste limitée à 5-10 % de la capacité totale qui m’est octroyée.
L’astuce est donc d’utiliser Composer le plus possible.
Le seul problème ? Il est beaucoup moins intelligent que Claude.
Mes règles :
Utiliser Composer pour les tâches stupides ou répétitives : Par exemple, c’est le modèle parfait pour faire un commit. C’est le type de tâche où il a besoin de faire plusieurs tool calls et d’avoir le contexte de la conversation précédente.
J’ai beaucoup moins de problème à utiliser Composer dans une conversation existante, puisque je ne l’utilise pas à pleine capacité.
Dans le doute, essayer avec Composer : Même pour des questions simples, Composer arrive à se planter ou à me baratiner. Mais j’essaie. S’il arrive à m’aider, tant mieux. S’il n’y arrive pas, je recommence avec Claude.
Pour une tâche répétitive mais pas trop stupide, utiliser Sonnet : À mon sens, Sonnet reste meilleur que Composer et est toujours moins cher que Opus. Si j’ai besoin d’appliquer un pattern qui s’adapte au code dans toute ma codebase, je vais privilégier Sonnet. C’est assez simple, répétitif, mais je n’ai pas suffisamment confiance en Composer.
4. Aller plus loin : auditer sa baseline
Tout ce qu’on a vu jusqu’à maintenant s’attaque à la dynamique de la conversation : combien de tours, quelle taille de contexte, quel modèle. Et c’est là que les gains sont les plus impactants.
Mais il y a une autre couche importante : La baseline. Ce que Cursor envoie au modèle avant même que vous tapiez quoi que ce soit :
- Le prompt system
- Les descriptions des tools
- Les rules
- Les skills
- Les MCPs
Cette baseline est toujours là.
Et on l’a compris dans les sections précédentes : Elle sera ré-intégrée à chaque tour de chaque prompt.
Si je regarde mes statistiques Cursor, je vois que j’ai fait 343 prompts dans les 7 derniers jours. Si on compte une moyenne de 5 tours par prompt, ça veut dire que cette baseline a été envoyée dans l’API 1715 fois.
On comprend donc rapidement que si on arrive à réduire cette baseline, même de quelques milliers de tokens, ça peut réduire la consommation de millions de tokens à la fin du mois.
Le benchmark du « Salut »
Pour mesurer, il faut un protocole.
Le mien :
- J’ouvre une nouvelle conversation.
- Je sélectionne Claude Opus 4.6 + Thinking (le modèle que j’utilise pour du code complexe)
- Je tape le prompt suivant : « Salut »
Et je note le nombre de tokens utilisé.
Avec ma configuration initiale, ce simple « Salut » envoyait 28 358 tokens au modèle. Avant que Claude n’ait répondu un seul caractère.
Ce qui compose cette baseline
En demandant à mon agent d’introspecter son propre system prompt, j’ai pu décomposer ces 28K en sept couches :
| Couche | Estimation | Contrôle utilisateur |
|---|---|---|
| Core system prompt Cursor | ~4-5K | Aucun |
| Tool descriptions (Shell, Read, Grep, ~20 tools) | ~10-14K | Partiel |
| Rules globales | ~500-800 | Total |
| Skills Cursor | ~1-2K | Partiel |
| Skills de plugins | ~1-2K | Total |
| MCPs actifs | variable | Total |
| Contexte environnemental (fichiers ouverts, terminaux) | ~500-1K | Partiel |
Je n’ai quasiment aucun impact sur une grosse moitié de la baseline.
Les tool descriptions correspondent à un descripteur en JSON qui est envoyé au modèle. Il lui permet de savoir ce qui est disponible, à quoi ça sert, et comment l’utiliser.
Le reste, ce sont des choses que j’ai empilées au fil du temps. Et là, on peut couper.
Trois passes, -27 %
J’ai fait trois passes successives, en relançant le benchmark « Salut » entre chacune.
Passe 1 : Virer ce dont je n’ai pas besoin tout le temps
J’avais 3 serveurs MCPs actifs :
- Un “maison” pour accéder à de la connaissance interne
- Un pour Svelte que je n’utilise que dans un projet
- Un pour Excalidraw, que j’utilise aussi de manière très sporadique
J’avais également une rule datachamp.mdc qui donne du contexte sur l’agence, afin d’éviter de le répéter systématiquement à l’agent IA.
Ces outils sont inutiles 99% du temps, mais chargés 100% du temps.
J’ai juste eu besoin de les désactiver. Et il faut penser à les ré-activer quand j’en ai besoin.
Passe 2 : Bidouiller les paramètres Cursor
J’ai parcouru tous les menus des paramètres et pour chaque option j’ai testé avant/après si ça avait un impact sur la consommation du prompt.
Résultat :
| Option désactivée | Gain |
|---|---|
| Browser Automation | -1 700 tokens |
| Web Search Tool | -200 tokens |
| Web Fetch Tool | -100 tokens |
| Docs indexées | -400 tokens |
Le Browser Automation, je ne m’en sers absolument jamais.
Les “Web Search Tool” et “Web Fetch Tool” sont plus utiles pour moi. Mais là encore, je peux les activer quand j’en ai besoin, et les laisser off le reste du temps. Bon, pour 300 tokens de base, je pourrais les laisser activés.
Et la doc indexée, ce sont des vieilles docs de packages que j’avais rajoutées à un moment. Depuis que je les ai virées, je n’ai pas vraiment vu de différence.
Passe 3 : Les skills Cursor
Cursor propose des skills par défaut : Créer un hook, configurer une statusline, créer une rule, etc.
Chaque skill ajoute quelques centaines de tokens à la baseline. Et sur la douzaine qui sont installées par défaut, je n’en utilisais que 3 ou 4.
Je suis allé dans mes fichiers de config, et j’ai viré ce qui pouvait l’être.
Le récap final :
| Étape | Baseline |
|---|---|
| Initial | 28 358 |
| Passe 1 (MCPs, plugin Figma, rule datachamp) | 23 500 |
| Passe 2 (toggles Cursor) | 21 100 |
| Passe 3 (5 skills supprimées) | 20 700 |
| Final | -27 % sans perte de qualité |
On sent bien que chaque passe est un peu moins impactante que la précédente. On pourrait probablement aller encore plus loin, mais ça rapporte moins, et on commence à sacrifier des options pratiques.
Si je reprends mon calcul de plus tôt, j’économise ici 7658 tokens par tour.
Avec 343 prompts par semaine, et 5 tours par prompt, j’économise 13 millions de tokens par semaine, soit environ 50 millions de tokens par mois.
Sur une base d’environ 1 milliard de tokens en un mois, ça représente 5 %. Pas rien, mais pas révolutionnaire non plus.
Ce que ça change vraiment
Au-delà des économies de tokens, cet exercice m’a surtout permis de bien comprendre le mécanisme de facturation.
Avant, je regardais ma consommation de tokens sans comprendre.
Je voyais 3 millions de tokens utilisés pour corriger des erreurs de syntaxe, et je ne comprenais pas.
À côté, je posais des questions d’architecture complexes, et j’avais des réponses incroyables pour 300 000 tokens.
Maintenant, je sais anticiper le coût de mon prompt. Quand je vois l’agent IA enchaîner les tool calls les uns après les autres, sans les batcher, j’ai la petite goutte de sueur qui apparaît parce que je sais que ça va casquer.
À terme, on sait tous que les tarifs vont augmenter. Les providers sont dans une dynamique de conquête du marché, et on observe une pénurie de compute qui risque de s’aggraver dans les prochaines années. Maîtriser dès aujourd’hui ces mécanismes de facturation est crucial.
Commentaires