Vous vous souvenez du fichier de 39 043 lignes ?
Celui que je vous ai montré dans le premier article de cette série. Un seul module d’une application Shiny, un seul fichier, 39 043 lignes. Le truc le plus catastrophique qu’on m’ait jamais envoyé.
Dans ce premier article, on a parlé structure : comment découper l’application en modules, organiser le dossier R/, ranger chaque fichier à sa place.
Mais aujourd’hui, je veux qu’on fasse autre chose.
Je veux qu’on ouvre ce fichier, et qu’on regarde le code.
Voici un extrait de la partie UI :
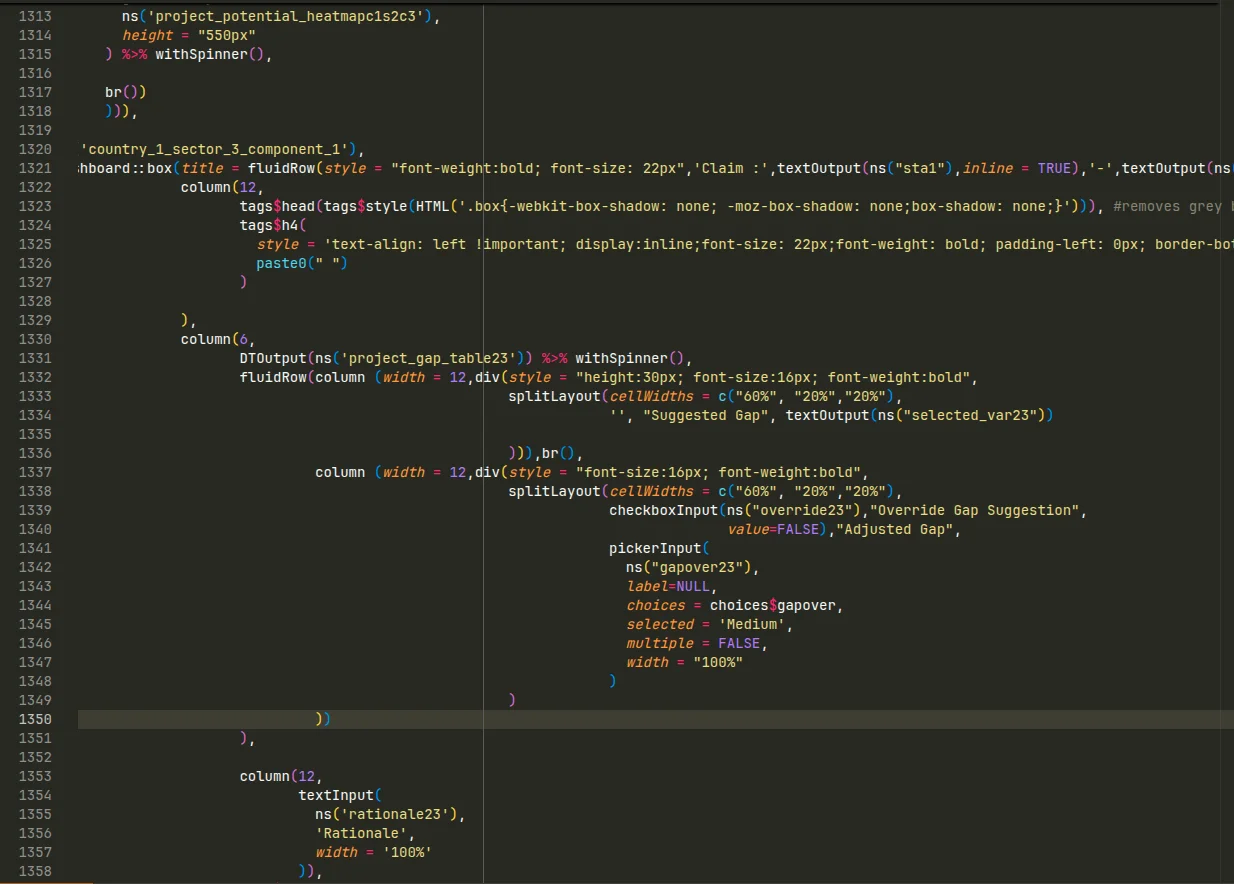
Deux repères pour lire cette capture :
- La barre verticale, c’est la limite des 80 caractères, une convention répandue pour éviter le scroll horizontal. La ligne 1321 la dépasse largement : pour la lire en entier, il faut scroller vers la droite.
- L’indentation ne suit pas la structure du code. Difficile de savoir, d’un coup d’œil, quel bloc se ferme à la ligne 1350.
Rien d’exceptionnel ici : c’est l’état de la plupart des bases de code qu’on récupère. Du code écrit au fil de l’eau, par des gens dont le métier n’est pas le développement, pour répondre à un besoin réel. Il fonctionne, mais il est devenu difficile à lire.
Travailler sur ce code, c’est comme si on vous demandait de reprendre un rapport de 50 pages, mais livré dans un fichier texte brut. Zéro formatage. Pas de titres, pas de paragraphes, des fautes à chaque ligne. Et la mission : « Rajoute ton expertise dans le document. »
Impossible. Avant d’apporter la moindre valeur, il faut d’abord remettre au propre.
Et c’est exactement ce qu’on fait. À chaque fois qu’on récupère une base de code client, la première étape, avant même de penser à la moindre nouvelle fonctionnalité, c’est le nettoyage.
Sur ce projet en particulier, trois symptômes ressortaient immédiatement :
1. L’indentation anarchique. Vous l’avez vue sur la capture. Quand l’indentation ne reflète plus la structure du code, chaque relecture devient un exercice de déchiffrage. On ne sait plus quel bloc contient quoi, ni où il se termine.
2. Le nommage hasardeux. Mon exemple préféré : la variable project_gap_table_prep. Elle existait en plus de 60 variantes dans le fichier. project_gap_table_prep5, project_gap_table_prep23, project_gap_table_prep71, project_gap_table_prepc2s3, project_gap_table_prepc3s3c3…
254 occurrences au total. Aucune logique apparente. Pour l’anecdote, j’ai passé mes premiers jours sur le projet à construire une table de correspondance entre les variables, juste pour comprendre qui était qui.
3. La répétition massive. En creusant, on a fini par comprendre les suffixes : c2s3 voulait dire « component 2, sector 3 ». Autrement dit, le même bloc de code était copié-collé pour chaque combinaison, avec juste le suffixe qui changeait. C’est ça, le secret des 39 043 lignes. Ce n’est pas une application gigantesque. C’est une application moyenne, dupliquée des dizaines de fois.
Le plus frustrant dans tout ça ? Cette application fonctionnait. Elle tournait en production, les utilisateurs s’en servaient. Le code « tombait en marche ».
Mais chaque évolution était un calvaire. Chaque bug, une chasse au trésor. Et le client le savait, c’est bien pour ça qu’il nous a appelés.
C’est toute la différence entre du code qui marche et du code de qualité. Et c’est le sujet de ce troisième article de la série sur les bonnes pratiques de développement Shiny.
Au programme :
- Adopter des standards de code, pour que le code soit cohérent et lisible
- Automatiser le respect de ces standards avec
lintretstyler - Les principes du code propre : nommage, factorisation, fonctions courtes
- Gérer les erreurs proprement avec
logger - Et une introduction aux tests, pour que le code reste robuste dans le temps
C’est parti.
1. Adopter des standards de code
Commençons par une question toute bête : pourquoi le fichier de tout à l’heure est-il si pénible à lire ?
Ce n’est pas (que) une question de compétence. Le développeur qui l’a écrit connaissait Shiny, l’application fonctionnait. Non, le vrai problème, c’est l’incohérence.
Une ligne indentée avec 2 espaces, la suivante avec 7. Parfois les arguments sont nommés, d’autres fois non. Parfois on utilise des guillements simples, d’autres fois des guillements doubles. Parfois on utilise du camelCase, d’autres fois du snake_case.
Chaque incohérence, prise individuellement, est insignifiante. Mais accumulées sur des milliers de lignes, elles créent un bruit de fond permanent. Votre cerveau passe son temps à décoder la forme au lieu de comprendre le fond.
C’est exactement l’effet des fautes d’orthographe dans un rapport : chaque faute casse la lecture. Et au bout de la dixième, un doute s’installe. Si l’auteur n’a pas soigné la forme, est-ce qu’il a soigné le raisonnement ?
Pour le code, c’est pareil. Et la solution porte un nom : les standards de code.
Un standard de code, c’est un ensemble de règles, arbitraires pour la plupart, qui répondent une bonne fois pour toutes à toutes ces micro-questions. Combien d’espaces pour l’indentation ? Quels guillemets ? Quel style de nommage ?
L’intérêt n’est pas que ces règles soient les « meilleures ». L’intérêt, c’est qu’elles soient appliquées partout, par tout le monde, tout le temps.
Parce qu’un code cohérent, c’est un code où votre cerveau peut se mettre en pilote automatique sur la forme, et consacrer 100 % de son attention au fond.
Nos standards à nous
Je vous partage les règles qu’on applique chez Data Champ’ sur tous nos projets. Vous n’êtes pas obligés d’adopter les mêmes. Mais si vous n’avez encore aucun standard, prenez ceux-là, ils ont fait leurs preuves. Par ailleurs, ils sont très fortement inspirés du Tidyverse style guide.
L’indentation : 4 espaces.
Pas de tabulations, pas de 2 espaces. Quatre. C’est plus aéré, et ça rend la hiérarchie des blocs immédiatement visible. C’est d’ailleurs pour préserver ces 4 espaces qu’on utilise la syntaxe particulière des modules présentée dans l’article sur la structure.
La longueur de ligne : 80 caractères en cible, 120 en limite dure.
La barre verticale de la capture d’écran, vous vous souvenez ?
Au-delà de 80 caractères, on prend le risque d’avoir un scroll horizontal, qu’on veut absolument éviter.
L’idéal, c’est max 80. En pratique, on a une certaine tolérance, mais à partir de 120 on bloque carrément les Merge Requests.
Le nommage : snake_case, descriptif, en minuscules.
work_packages plutôt que wp. selected_country plutôt que sc1. Et surtout, pas de project_gap_table_prepc2s3c3 : si vous avez besoin d’un suffixe cryptique pour distinguer deux variables, c’est que le problème est ailleurs (on y revient dans la section sur la répétition).
L’assignation : <- pour assigner, = pour les arguments.
production_year <- 2025
data <- some_function(
argument_1 = 1,
argument_2 = 2
)Les appels de fonction multi-lignes : un argument par ligne, tous nommés, parenthèse fermante sur sa propre ligne.
C’est le format que vous voyez juste au-dessus. Dès qu’un appel ne tient plus confortablement sur une ligne, on le déplie. Résultat : plus de scroll horizontal, et la parenthèse fermante indique sans ambiguïté où le bloc se termine.
Les guillemets : doubles.
"comme ça", jamais 'comme ça'. Arbitraire ? Complètement. Mais appliqué partout.
Le pipe : le pipe natif |>.
Depuis R 4.1, R a son propre pipe. Plus besoin de %>% et de sa dépendance à magrittr.
Les packages : toujours préfixés avec ::.
On écrit data.table::fread(), shinyWidgets::pickerInput(), DBI::dbGetQuery(). Comme ça, l’origine de chaque fonction est explicite, et on évite les conflits de noms entre packages.
Les seules exceptions : les packages où le préfixe nuit vraiment à la lisibilité, comme ggplot2 (imaginez préfixer chaque aes()…) ou les opérateurs spéciaux de data.table. Ceux-là sont chargés via library() dans le global.R, et c’est tout.
La documentation : roxygen2 pour toutes les fonctions model, service et helpers.
#' Get all projects
#'
#' @param conn Database connection (pool or DBI connection).
#' @return `data.table` with all columns of the `project` table.
project_model_get_all <- function(conn) {
data.table(DBI::dbGetQuery(
conn = conn,
statement = "SELECT * FROM project ORDER BY name"
))
}Un titre, les paramètres, ce que la fonction retourne. Pas besoin de plus. (Et si les familles model, service et helpers ne vous disent rien, tout est expliqué dans l’article sur la structure.)
Voilà pour l’essentiel. Vous remarquerez qu’aucune de ces règles n’est compliquée. Le défi n’est pas de les comprendre.
Le défi, c’est de les appliquer. Partout. Tout le temps. Même un vendredi à 18h quand on veut juste finir sa feature.
Et là, j’ai une bonne nouvelle pour vous.
2. Automatiser le respect des standards avec lintr et styler
Reprenons l’analogie du rapport.
Quand vous l’écrivez sur Word, le logiciel ne corrige pas les fautes à votre place. Il souligne les fautes, les tournures bancales, les incohérences. Ensuite, c’est à vous de corriger.
Pour le code R, ce détecteur de fautes existe. Il s’appelle lintr.
lintr : le contrôle des règles
lintr parcourt votre code et liste toutes les violations des règles : indentation incohérente, lignes trop longues, variables mal nommées, code mort, mauvaises pratiques.
Pour analyser tout un projet :
lintr::lint_dir()Et vous obtenez la liste complète des problèmes, fichier par fichier, ligne par ligne, directement cliquable dans RStudio ou VSCode.
La configuration passe par un fichier .lintr à la racine du projet. Vous vous souvenez peut-être de ce fichier : il apparaissait dans la structure de projet du premier article, avec la promesse d’y revenir. Nous y voilà.
Voici le nôtre, identique sur tous nos projets :
linters: linters_with_defaults(
line_length_linter(120),
object_usage_linter = NULL,
brace_linter = NULL,
object_length_linter(50),
trailing_whitespace_linter = NULL,
indentation_linter(4))
encoding: "UTF-8"Le principe : on part des règles par défaut avec linters_with_defaults() (qui incluent déjà le snake_case, les espaces après les virgules, etc.), puis on ajuste. On y retrouve les standards de la section précédente : 120 caractères en limite dure, 4 espaces d’indentation. Et on désactive quelques linters qui, sur nos projets, génèrent plus de bruit que de valeur, comme object_usage_linter et ses faux positifs en pagaille dans une application Shiny.
Brancher lintr sur la CI : le garde-fou ultime
Lancer lintr à la main, c’est bien. Mais on retombe sur le problème du vendredi 18h : le jour où on est pressé, on oublie.
La solution, c’est de rendre le contrôle obligatoire et automatique : on intègre lintr dans la pipeline CI/CD du projet. À chaque push, la pipeline lance le linter, et si le code ne respecte pas les standards, la pipeline échoue. Impossible de merger.
Ça peut paraître brutal. En pratique, c’est libérateur :
- Plus besoin de faire la police pendant les reviews de code. La machine s’en charge, sans état d’âme et sans froisser personne.
- Le standard est garanti sur 100 % du code mergé. Pas « la plupart du temps ». Toujours.
- Et un nouveau développeur qui rejoint le projet découvre les règles immédiatement, dès son premier push.
Je ne détaille pas ici la mise en place de la pipeline elle-même, ça mériterait un article à part entière. Retenez l’idée : le respect des standards ne doit pas reposer sur la discipline humaine, mais sur un contrôle automatique.
styler : pour vous faciliter la vie
lintr signale les problèmes, mais ne les corrige pas. Pour la correction automatique, il existe un deuxième outil : styler.
styler prend votre code et le reformate selon un style donné : indentation, espaces autour des opérateurs, position des accolades, etc.
Sur un fichier :
styler::style_file("R/100_home_server.R")Sur tout un dossier :
styler::style_dir("R/")Et c’est tout. Les indentations anarchiques, les espaces manquants après les virgules, les accolades mal placées : tout est corrigé d’un coup. Et styler ne modifie que la forme du code, jamais son comportement : aucun risque de casser quoi que ce soit.
Pour être honnête avec vous : au quotidien, je n’utilise quasiment jamais styler.
Pas parce que l’outil est mauvais. Mais parce qu’à force d’appliquer les standards, ils sont devenus des réflexes. Je n’écris plus de ligne mal indentée, comme vous ne faites plus de faute d’accord sur un participe passé simple. C’est ça, la vraie destination : les règles finissent par s’écrire toutes seules.
Le cas où styler brille vraiment, c’est la reprise d’une base de code sale. Face à un fichier comme celui du début de l’article, un styler::style_dir() fait gagner des heures de remise en forme manuelle.
Un conseil si vous le faites : passez styler dans un commit dédié, qui ne contient rien d’autre. Sinon, le jour où vous chercherez l’origine d’un changement dans l’historique Git, le reformatage massif viendra tout polluer.
Avec des standards écrits et lintr branché sur la CI, vous avez réglé la question de la forme. Définitivement.
Mais ni lintr ni styler ne renommeront vos variables cryptiques, et aucun outil ne dédoublonnera votre code à votre place. Un code peut être parfaitement formaté et rester un cauchemar : 60 variantes de project_gap_table_prep joliment indentées en snake_case, ça reste 60 variantes de project_gap_table_prep.
Il est temps de parler du fond : le code propre.
3. Écrire du code propre
Reprenons nos trois symptômes du début :
- L’indentation anarchique ? Réglée. C’est exactement ce que les standards et
lintrviennent d’éliminer. - Le nommage hasardeux ? Toujours là.
- La répétition massive ? Toujours là aussi.
Et pour ces deux-là, aucun outil automatique ne viendra vous sauver. Renommer une variable, factoriser du code dupliqué, ce sont des décisions qui demandent de comprendre ce que fait le code.
C’est ce qu’on appelle le code propre : au-delà de la forme, écrire du code dont la logique elle-même est limpide.
Le sujet remplit des livres entiers (Clean Code, pour ne citer que le plus connu). Je vais me concentrer sur les trois principes qui transforment le plus nos projets Shiny.
Des noms qui racontent ce que fait le code
On lit du code beaucoup plus souvent qu’on n’en écrit. Vous écrivez une variable une fois, vous la relirez des dizaines de fois, parfois des années plus tard, parfois sans aucun souvenir du contexte.
Le nom d’une variable ou d’une fonction, c’est donc la documentation la plus lue de votre projet. Autant qu’il travaille pour vous :
- Une variable dit ce qu’elle contient :
selected_country,monthly_revenue,projects_with_gaps. - Une fonction commence par un verbe ou suit une convention claire :
format_currency(),client_model_get_all().
Le test est simple : si vous devez ouvrir la fonction pour comprendre ce qu’elle fait, le nom est raté.
Maintenant, regardez project_gap_table_prep23.
Que contient cette variable ? En quoi est-elle différente de project_gap_table_prep71 ? Aucun moyen de le savoir sans remonter tout le code. C’est exactement ce qui m’a coûté mes premiers jours sur le projet, à reconstituer la fameuse table de correspondance.
Mais le plus intéressant, c’est que ce nommage est un symptôme. Si vous avez besoin d’un suffixe numérique pour distinguer 60 versions de la même variable, le problème n’est pas le nom.
Le problème, c’est qu’il y a 60 versions de la même variable.
Ne vous répétez pas
C’est le principe DRY : Don’t Repeat Yourself.
Souvenez-vous des suffixes du fichier de 39 043 lignes : c2s3 pour « component 2, sector 3 ». Le même bloc de code, copié-collé pour chaque combinaison, avec juste le suffixe qui change.
Pourquoi c’est grave ? Faites le calcul avec moi.
Vous trouvez un bug dans le tableau des écarts. Vous le corrigez. Sauf que ce code existe en 60 exemplaires. Vous venez de corriger 1 bug sur 60. Les 59 autres attendent tranquillement en production.
Et chaque évolution suit la même règle : tout changement doit être reporté 60 fois, à la main, sans en oublier un seul. C’est intenable.
La solution, vous la connaissez déjà si vous avez lu l’article sur la structure : la factorisation. Une fonction si c’est de la logique, un module Shiny si c’est un bloc d’interface avec sa logique réactive.
Au lieu de 60 copies :
output$project_gap_table23 <- DT::renderDataTable({
# 50 lignes de préparation de project_gap_table_prep23
})
output$project_gap_tablec2s3 <- DT::renderDataTable({
# les mêmes 50 lignes, pour project_gap_table_prepc2s3
})
# ... répété pour chaque combinaisonUn seul module, appelé avec des paramètres :
gap_module_ui(ns("gap"), data = data)Le bloc n’existe plus qu’à un seul endroit. Un bug ? Une correction. Une évolution ? Une modification. Et les project_gap_table_prep23 disparaissent d’eux-mêmes : à l’intérieur du module, la variable s’appelle simplement project_gap_table.
Petite nuance avant de partir factoriser toute votre application : la duplication ponctuelle n’est pas un crime. Copier-coller un bloc une fois, ça arrive, et c’est parfois plus lisible qu’une abstraction prématurée. Ma règle pratique : à la troisième copie, on factorise.
Des fonctions courtes, une seule responsabilité
Dernier principe, et c’est le prolongement direct de la Séparation des Responsabilités vue dans le premier article : une fonction doit faire une seule chose.
Comment savoir si c’est le cas ? Encore une fois, le nommage vous tend un miroir. Si vous arrivez à nommer votre fonction simplement (format_currency, compute_gap_score), c’est bon signe. Si le nom honnête serait load_and_filter_and_compute_and_plot, vous avez quatre fonctions déguisées en une.
L’avantage des fonctions courtes à responsabilité unique :
- Elles sont faciles à comprendre : tout tient sur un écran, pas besoin de scroller pour suivre la logique.
- Elles sont faciles à réutiliser : une fonction qui fait une chose s’emboîte partout. Une fonction qui en fait quatre, nulle part.
- Elles sont faciles à tester : on y reviendra dans la section sur les tests.
Et où ranger toutes ces fonctions ? C’est exactement le rôle des familles helpers, model et service présentées dans l’article sur la structure. La séparation model/service en particulier, c’est le principe de responsabilité unique appliqué à l’échelle du projet : l’accès aux données d’un côté, la logique métier de l’autre.
Le résultat : avant / après
Alors, ça donne quoi, tout ça, appliqué au fichier de 39 043 lignes ?
Voici grosso modo le même morceau de code que la capture du début, après remise au propre :
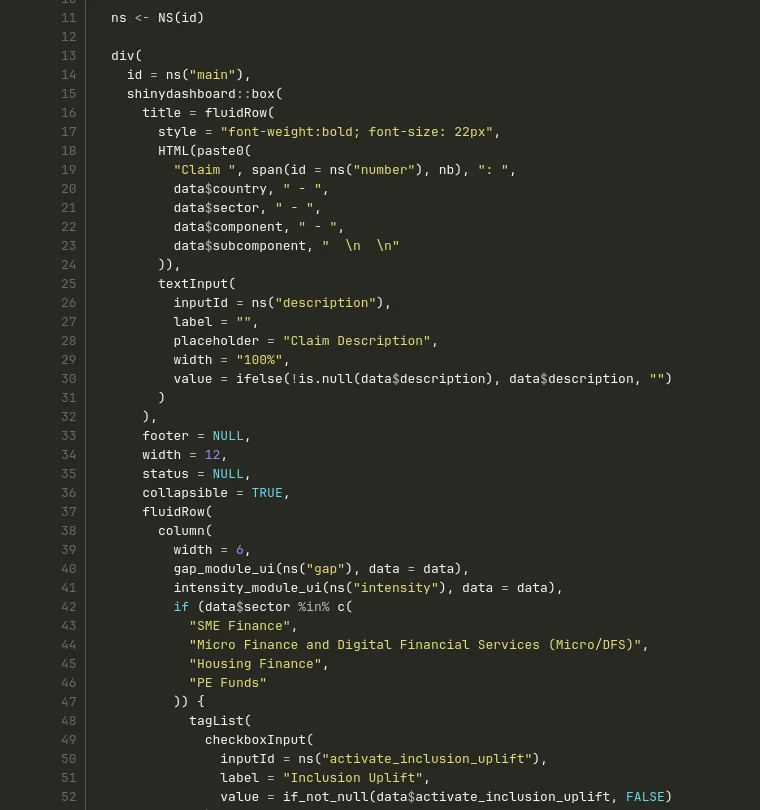
Comparez avec la capture du début. C’est plus clair, plus aéré, lisible de haut en bas sans scroll horizontal. L’indentation raconte la structure. Et vous pouvez voir la factorisation à l’œuvre : les appels à gap_module_ui() et intensity_module_ui() remplacent des blocs entiers qui étaient auparavant copiés-collés.
« Oui mais ça prend plus de lignes ! »
Localement, c’est vrai : le code déplié, un argument par ligne, prend de la place. Mais à l’échelle du projet, le verdict est sans appel :
- Avant : 39 043 lignes, dans un seul fichier.
- Après : environ 15 000 lignes, réparties sur une trentaine de fichiers.
Trois fois moins de code, pour exactement les mêmes fonctionnalités. C’est ça, l’effet de la factorisation. Et chaque fichier, pris individuellement, se lit comme un chapitre : un titre clair, une responsabilité, une longueur raisonnable.
Le rapport de 50 pages en fichier texte brut est devenu un document structuré, avec une table des matières, des chapitres, et zéro faute. On peut enfin y ajouter notre expertise.
Le code est propre et lisible. Mais propre ne veut pas dire infaillible : il reste à gérer ce qui se passe quand les choses tournent mal.
4. Gérer les erreurs proprement
Une application en production, ça vit. Et parfois, ça casse : la base de données ne répond plus, une API externe renvoie n’importe quoi, un utilisateur uploade un fichier inattendu.
La question n’est pas de savoir si une erreur va se produire, mais quand. Et surtout : qu’est-ce qui se passe à ce moment-là ?
Dans une application Shiny sans gestion d’erreurs, la réponse est brutale : l’écran devient gris. La session plante, l’utilisateur perd son travail en cours, et vous, vous n’avez aucune trace de ce qui s’est passé. Vous l’apprendrez par un email du client : « L’application ne marche plus. »
Du code de qualité, c’est aussi du code qui échoue proprement : l’utilisateur est prévenu avec un message clair, et vous gardez une trace exploitable pour diagnostiquer. Deux outils pour ça.
logger : des traces exploitables
Premier réflexe à abandonner : les print() et les cat() éparpillés dans le code pour « voir ce qui se passe ».
À la place, on utilise le package logger. Même effort d’écriture, mais avec trois avantages décisifs :
- Chaque message est horodaté automatiquement.
- Chaque message a un niveau :
INFOpour les opérations normales,WARNpour les échecs récupérables,ERRORpour les échecs bloquants,DEBUGpour les traces de développement. - On peut filtrer par niveau : les traces
DEBUGs’affichent en développement, mais disparaissent en production, sans toucher au code.
logger::log_info("Chargement des projets : {nrow(projects)} lignes")
logger::log_warn("API météo indisponible, affichage sans les prévisions")
logger::log_error("Échec de l'écriture en base : {e$message}")(Oui, logger supporte l’interpolation à la glue nativement : les {} sont évalués dans le message.)
Sur nos projets, chaque bloc significatif d’un module commence par une ligne de log avec un format systématique, "{numéro} - {module} - {bloc}" :
logger::log_info("521 - projects - save")Résultat : quand quelque chose se passe mal en production, les logs racontent l’histoire. Quel module, quel bloc, dans quel ordre, et quel message d’erreur. Le diagnostic qui prenait une après-midi prend dix minutes.
tryCatch + un handler centralisé
Deuxième outil : intercepter les erreurs là où elles peuvent se produire, avec tryCatch.
L’erreur classique (sans mauvais jeu de mots), c’est de réécrire la gestion à la main dans chaque tryCatch : un coup on log, un coup on affiche une notification, un coup on oublie la moitié. Encore un problème de cohérence.
Notre solution : un handler centralisé, défini une seule fois dans les helpers :
handle_shiny_error <- function(context) {
function(e) {
logger::log_error("{context}: {e$message}")
showNotification(
paste("Erreur :", e$message),
type = "error",
duration = 10
)
}
}Et à l’usage, chaque opération risquée (écriture en base, appel d’API) est enveloppée comme ceci :
observeEvent(input$save, {
tryCatch({
project_model_update(conn = conn, project = project)
projects_refresh(projects_refresh() + 1L)
removeModal()
showNotification("Projet enregistré.", type = "message")
}, error = handle_shiny_error("521/save_project"))
})Si l’écriture en base échoue, plus d’écran gris : l’utilisateur voit une notification d’erreur claire, l’application continue de tourner, et le log contient le contexte exact (521/save_project) avec le message d’erreur.
Un dernier piège à éviter : le tryCatch qui avale les erreurs en silence, du genre error = function(e) NULL. C’est pire que pas de gestion du tout. L’application semble fonctionner, mais les données ne sont pas sauvegardées, et personne ne le sait. Une erreur doit toujours laisser une trace.
5. Écrire des tests
Dernier pilier de la qualité, et je vous vois venir : « Des tests ? Pour une application Shiny ? On n’a pas le temps. »
Laissez-moi vous raconter pourquoi on en écrit quand même.
Souvenez-vous de la factorisation de la section 3 : 60 copies d’un bloc fusionnées en un seul module. Une question aurait dû vous traverser l’esprit : comment on sait qu’on n’a rien cassé ?
Vérifier à la main les 60 combinaisons, dans toutes les configurations possibles, après chaque modification ? Personne ne le fait. Et c’est exactement comme ça que les régressions arrivent en production.
La solution, c’est d’écrire du code qui vérifie le code : des tests automatisés. On les écrit une fois, on les relance à volonté, et chaque refactoring devient une opération sereine : si les tests passent encore, le comportement est préservé.
À quoi ça ressemble
En R, le package de référence est testthat. Voici un test sur une fonction helpers :
describe("format_currency", {
it("should format a number with thousands separator and euro symbol", {
expect_equal(format_currency(1234.5), "1 234,50 €")
})
it("should return an empty string when the input is NA", {
expect_equal(format_currency(NA), "")
})
})La structure se lit toute seule : un describe par fonction, un it par comportement attendu. On vérifie le cas normal, et surtout les cas limites (le NA qui finira forcément par arriver).
Et vous voyez maintenant pourquoi j’insistais sur les fonctions courtes à responsabilité unique : une fonction qui fait une seule chose se teste en trois lignes. Une fonction de 400 lignes qui charge, filtre, calcule et affiche, c’est un cauchemar à tester. La qualité du code et la testabilité, c’est la même bataille.
Quoi tester (et quoi ne pas tester)
Le piège des débutants, c’est de vouloir tout tester, s’épuiser, et abandonner. Tous les tests ne se valent pas. Avant d’écrire un test, je me pose trois questions :
- Quel bug concret ce test détecterait-il ?
- Est-ce qu’il survivrait à un refactoring qui ne change pas le comportement ? (Si non, il testera l’implémentation plutôt que le comportement, et vous gênera plus qu’il ne vous protégera.)
- Est-ce qu’il casserait si j’introduisais une erreur de logique ? (Si non, il ne protège rien.)
En pratique, sur nos projets Shiny, l’essentiel des tests porte sur les fonctions model (l’accès aux données, testé contre une vraie base de test) et service (la logique métier, là où vivent les calculs et donc les bugs). L’interface elle-même, on la teste très peu : c’est coûteux, fragile, et les bugs y sont plus rares.
Par où commencer : la stratégie réactive
Reste la vraie question : comment on s’y met, concrètement ?
Parce que soyons honnêtes sur le point de départ. La plupart des applications Shiny démarrent comme des prototypes : un seul développeur, qui a toute l’application en tête, et qui la teste à la main en trente secondes. À ce stade, des tests automatisés n’apporteraient pas grand-chose. Zéro test, c’est le point de départ normal, pas une faute.
Le problème arrive plus tard, quand le prototype a grossi, que la mémoire ne suffit plus, et que vous voilà devant des milliers de lignes sans aucun test. L’idée de rattraper tout le retard d’un coup est paralysante. Alors on ne fait rien.
Voici l’astuce pour démarrer sans douleur : adoptez une stratégie réactive. N’essayez pas de couvrir l’existant. Attendez le prochain bug.
Quand un bug apparaît :
- Vous vous assurez que le code concerné est propre. Si la logique fautive est noyée dans un gros bloc, vous la factorisez d’abord en fonction (et vous savez faire, c’était la section 3).
- Vous écrivez un ou plusieurs tests qui reproduisent le bug. Ils échouent, c’est normal : c’est la preuve qu’ils détectent bien le problème.
- Vous corrigez le bug. Les tests passent au vert.
Coût : quelques minutes de plus que la correction seule. Bénéfice : ce bug-là ne reviendra jamais. Parce qu’il n’y a rien de plus frustrant que de corriger le même bug pour la troisième fois, six mois après les deux premières.
Et l’effet cumulé est redoutable. Chaque bug enrichit la suite de tests, exactement là où le code en a le plus besoin : les zones fragiles sont, par définition, celles où les bugs apparaissent. Au fil des mois, sans jamais avoir bloqué une semaine pour « écrire les tests », vous vous retrouvez avec une application de plus en plus robuste.
Je m’arrête là pour aujourd’hui. Les tests méritent bien plus que deux sous-sections : l’infrastructure, les tests d’intégration avec une base de données, les mocks, la stratégie complète. Ce sera l’objet d’un article dédié dans les prochains mois.
Retenez l’essentiel : les tests ne sont pas un luxe de grande équipe. C’est ce qui vous permet de modifier votre code sans avoir peur.
Conclusion
Reprenons le chemin parcouru depuis le fichier de 39 043 lignes :
- Des standards de code ont éliminé les incohérences de forme : indentation, nommage, formatage. Le bruit de fond a disparu.
lintret la CI ont rendu ces standards automatiques et garantis, sans dépendre de la discipline de chacun.- Les principes du code propre (nommage descriptif, factorisation, responsabilité unique) ont divisé la taille du code par trois.
loggeret les handlers d’erreurs centralisés ont rendu l’application diagnosticable : fini les écrans gris mystérieux.- Et les tests verrouillent le tout : le code peut évoluer sans peur de la régression.
Le rapport de 50 pages illisible est devenu un document structuré et relu. Et surtout, il va le rester : c’est toute la différence entre un nettoyage ponctuel et un système de qualité.
C’est la vraie leçon de cet article. La qualité du code n’est pas un grand ménage qu’on fait une fois. C’est un ensemble de règles simples, outillées et automatisées, qui s’appliquent à chaque ligne écrite. Au début, ça demande un effort conscient. Au bout de quelques mois, c’est un réflexe.
Cet article est le troisième d’une série de six articles pour passer d’un prototype Shiny à une application industrialisée :
- Structurer le projet
- Assurer la reproductibilité avec
renv - Assurer la qualité du code (l’article que vous venez de lire)
- Soigner la conception logicielle (à venir)
- Déployer l’application sur une VM
- Sécuriser l’application avec Auth0
Rendez-vous au prochain article pour parler de conception logicielle.
Commentaires