Le 18 mai 2021, je reçois un message d’un prospect. Pas de détour, il va droit au but : il a besoin d’aide, et vite.

C’est clair, c’est précis, et… c’est urgent.
On organise très rapidement un premier call pour dégrossir le besoin. Le client me présente les fonctionnalités de l’application existante, et puis on passe au partage d’écran pour me montrer le code de l’appli.
Le client continue de parler, mais je vois un détail sur l’écran : je n’arrive plus à écouter.
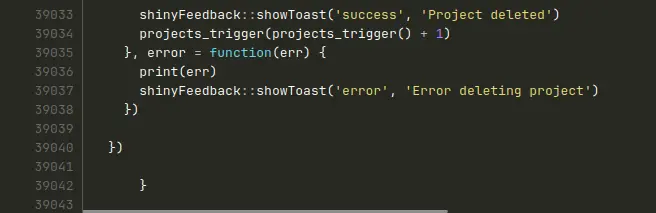
Le fichier qu’on me présente, qui n’est qu’un seul module de l’application parmi d’autres… fait 39 043 lignes.
Je n’avais jamais vu ça.
Je n’avais même jamais ENVISAGÉ ça.
Comment on arrive à s’y retrouver dans un fichier aussi énorme ?!
Et est-ce que j’ai mentionné que le client voulait rajouter de nouvelles features en urgence ?
Un enfer.
Ce n’est pas rare que les bases de code qu’on nous envoie ne soient pas très organisées.
Les utilisateurs de R sont rarement de purs développeurs en R. La plupart du temps, ils ont un vrai métier à côté, et R n’est qu’un outil parmi d’autres.
Et en plus, les scripts R ont une durée de vie courte. Une fois l’analyse de données terminée. on ne va plus jamais toucher au script.
Tous ces éléments font que ce n’est pas si étonnant si on se retrouve régulièrement à récupérer du code bien pourri.
D’ailleurs, moi aussi j’ai écrit du code bien pourri pendant mes premières années.
Mais au fil des années, je me suis amélioré.
Parce que le code pourri, c’est sympa au début. On se prend pas la tête, on développe rapidement, ça tombe en marche donc on continue.
Sauf qu’au bout d’un moment…
C’est ingérable.
Chaque changement devient super lourd. L’appli est lente. On se dit qu’il faudrait faire une refonte, sauf que ça va prendre des semaines !
Et quand on fait une application Shiny, c’est pas juste pour une fois. On veut que l’application puisse vivre des années et évoluer avec de nouvelles fonctionnalités. Peut-être même que l’équipe de développement va changer, et d’autres développeurs vont devoir s’approprier le code.
Pas question de laisser le code mourir.
Alors j’ai appris les bonnes pratiques. J’ai lu des bouquins. J’ai essayé des frameworks Shiny comme golem ou rhino.
Et au fil des années, à force d’accumuler ce que j’aimais bien ici et là, ce que je trouvais efficace, mais aussi en me trompant fort sur certaines expérimentations, j’ai développé ma propre méthodologie.
C’est cette méthodo qu’on utilise aujourd’hui à Data Champ’, le fruit de plusieurs années d’expérimentation et de rafinement.
Alors si vous aussi :
- vous avez déjà développé quelques applications Shiny,
- vous cherchez maintenant à structurer votre code de manière plus professionnelle,
- ainsi qu’à améliorer la maintenabilité et la qualité du code que vous écrivez,
- et à mettre en place de bonnes pratiques de collaboration au sein de votre équipe,
cet article est fait pour vous.
Vous connaissez déjà les bases de Shiny. Maintenant il est temps de passer au niveau supérieur.
L’approche que je présente ici consiste en quatre grandes étapes, que nous allons explorer en détail :
- 1. Structurer le projet : D’abord, on va voir comment organiser vos fichiers et dossiers, découper votre application en modules, et s’assurer que chaque ligne de code est rangée à la bonne place.
- 2. Gérer l’environnement : Ensuite, on va discuter de l’utilisation de
renv, pour la reproductibilité, mais aussi comment sécuriser les variables sensibles, et comment s’assurer que l’application fonctionne dans tous les environnements où elle est amenée à vivre. - 3. Assurer la qualité du code : Là on va discuter code propre, standards de code, principes généraux de programmation, et comment de manière générale écrire du code de qualité qui est facile à maintenir et robuste à l’apparition de bugs (via l’écriture de tests notamment).
- 4. Faciliter la collaboration et le déploiement : Finalement, comment utiliser Git, comment automatiser avec des pipelines CI/CD, et comment documenter votre projet pour que vos collègues puissent le comprendre et y contribuer.
Il y a beaucoup de choses à dire. C’est pourquoi dans cet article, nous allons déjà traiter de la première partie : Structurer un projet de code R Shiny.
L’objectif de cette série d’articles est de présenter une vue d’ensemble, qui relie toutes les pièces du puzzle les unes avec les autres sur la manière dont notre équipe crée des applications Shiny.
Toutes les recommendations ne vous conviendront pas, et c’est OK.
Piochez ce qui vous intéresse. Délaissez le reste. Ou revenez-y plus tard, quand vous serez prêts.
Lors de ma récente participation au Shiny Tiny Hackathon organisé par Appsilon, j’ai mis en place la plupart des principes que je présente ci-dessous. Je dis « la plupart » parce qu’on n’avait que 4 heures, donc on n’y retrouvera pas tout. Mais on n’est pas loin.
Vous pouvez déjà avoir un aperçu du code en suivant ce lien :
https://gitlab.datachamp.fr/charles/shiny-tiny-hackathon
Et voici à quoi ressemble l’appli :
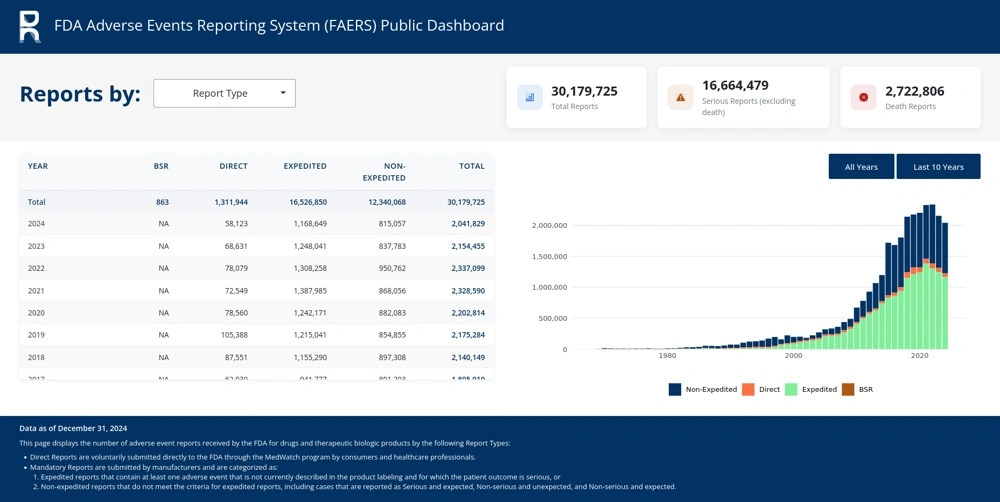
Étape par étape, je vais vous montrer les choix structurels qui ont été faits, et surtout pourquoi ils ont été faits.
1. Faut-il absolument faire un package ?
La première application Shiny que j’ai codée en 2016 était une refonte. À l’époque, personne ne savait vraiment ce qu’il faisait en terme de développement Shiny. La techno n’avait que 4 ans.
Mais j’avais lu ici et ailleurs que le mieux pour structurer son application, c’était de faire un package.
Il n’y avait que des avantages :
- Ça standardise la manière de structurer le projet (
R/,inst/,man/, etc.) - Ça donne un cadre pour écrire une vraie documentation des fonctions avec
roxygen2 - Les dépendances sont listées dans le champ
Importsdu fichierDESCRIPTION, ce qui évite les oublis - Les tests unitaires sont intégrés avec
testthat - On peut indiquer un numéro de version pour l’appli/package
- On peut mettre son appli/package sur Github pour que n’importe qui puisse l’installer facilement
Les avantages sont nombreux. J’aimais particulièrement la notion de standardisation et d’universalité. Adopter la structure de package permettait de garantir que d’autres développeurs soient tout de suite familiers avec mon code.
Quelques années plus tard, j’ai testé golem, l’outil de création de l’équipe ThinkR qu’ils avaient open sourcé. Là aussi, on crée un package.
Mais, comme pour tout, il y a aussi des inconvénients :
- Il faut respecter la structure de package : Pas de
app.R, encore moins deglobal.R,ui.R,server.Rqu’on laisserait à la racine du projet. Tout doit tenir dans des fonctions. - Pas non plus de dossier
www/qui contiendrait les ressources de l’application (images, etc.). Une alternative est de les stocker dansinst/www/et ensuite le déclarer avecshiny::addResourcePath(), mais ce n’est pas standardisé. - Le package apporte plus de choses que nécessaire, et ces fonctionnalités supplémentaires viennent avec leurs contraintes. Par exemple, la documentation n’a pas besoin d’être aussi formatée que ce que propose
roxygen2. Autre exemple, la formalisation autour des fichiersDESCRIPTIONetNAMESPACEn’est pas nécessaire. - Il faut gérer le build et l’installation du package.
Ces inconvénients m’ont fait réaliser que j’adorais l’idée d’utiliser une structure de package, mais qu’elle apportait aussi une certaine complexité dont je n’avais pas besoin.
J’ai adopté une approche à mi-chemin : J’ai gardé tout ce que j’aimais de la structure de package, et j’ai viré tout le reste.
À la fin, j’ai tous les avantages. Et aucun inconvénient.
Est-ce que j’ai une vraie structure de package ? Non. Je n’en ai pas besoin.
- À la racine de mon projet, j’ai mes fichiers fondamentaux :
global.R,ui.R,server.R, ce que le package m’empêchait de faire. - Tous les autres scripts R sont des fichiers de fonctions que je stocke dans un dossier
R/. - Toutes mes ressources (images, css, etc.) sont dans le dossier
www/, comme Shiny le prévoit nativement. - Je n’ai pas besoin du
DESCRIPTIONpour gérer mes dépendances, puisque j’utiliserenv, qui garantit une meilleure reproductibilité. - Les tests n’ont pas besoin d’une structure de package pour tourner sur l’ensemble de mon projet.
En Shiny, pas besoin de faire un package pour que les fonctions définies dans le dossier R/ soient disponibles. Elles sont automatiquement sourcées par Shiny depuis la version 1.5 !

Faire un package, c’est un piège de perfectionniste.
On peut très bien avoir une structure de projet solide, maintenable, évolutive et standardisée, sans forcément cocher toutes les cases du “package parfait”.
Pour moi, les trois fichiers global.R, ui.R, et server.R sont les piliers fondamentaux sur lesquels tout le reste de l’application est construite. Ils doivent être à la racine.
Pourquoi trois fichiers d’ailleurs ?
2. Les trois fichiers de base : global.R, ui.R, et server.R
Un fichier app.R, c’est bien pour démarrer, pour apprendre, mais ça va rarement très loin.
La dernière fois qu’on m’a envoyé une application Shiny qui tenait dans un app.R, le fichier faisait 5000 lignes et c’était incompréhensible.
Résultat ? On passe du temps à tout ranger avant même de commencer à faire du vrai travail utile.
La première étape, c’est déjà de découper ce fichier app.R en trois sous-fichiers :
global.R: Contient tout ce qui doit être initialisé au démarrage de l’application. Chargement de packages, de données, options R, etc. En général, ce fichier est très court.ui.R: Contient le code de l’interface utilisateur (UI).server.R: Contient la partie serveur, la fameusefunction(input, output, session) { ... }.
Ce simple découpage va déjà vous permettre :
- D’avoir des fichiers plus légers, plus faciles à maintenir.
- De bien séparer les responsabilités : L’initialisation, l’UI, et le serveur sont des concepts différents qui n’ont pas lieu d’être mélangés.
Ces fichiers sont la base de l’application Shiny : Ils doivent donc être placés à la racine du projet. Tous les autres fichiers de l’application vont être appelés à partir de ces trois fichiers de base.
La séparation des responsabilités (Separation of Concerns)
En développement logiciel, la « séparation des responsabilités » consiste à découper le code en parties distinctes, chacune ayant un rôle précis et limité.
Ce principe s'applique à toutes les échelles :
- Au niveau d'une fonction : Elle doit avoir une mission claire et unique.
- Au niveau d'un fichier : Chaque fichier regroupe des éléments qui partagent une même responsabilité (ex : interface utilisateur, logique métier, etc.).
- À l'échelle d'un projet : On sépare les modules, les tests, les ressources, etc.
L'objectif ?
- Rendre le code plus lisible et plus facile à maintenir.
- Limiter les effets de bord (un changement local n'a pas d'impact inattendu ailleurs).
- Faciliter le travail en équipe sans se marcher sur les pieds.
En résumé : Chaque brique du code doit avoir une mission claire, et s'occuper uniquement de ce qui la concerne.
Le fichier global.R
Il n’est pas évident d’appréhender ce qu’on met dans le global.R quand on n’a pas l’habitude. Je vous donne quelques exemples ci-dessous. On y trouve :
Le chargement des packages
Nous, on a une règle simple : On évite le plus possible de charger des packages entièrement au démarrage de l’appli. Mais certains, comme data.table ou ggplot2, sont souvent présents :
library(data.table)
library(shiny)
library(ggplot2)Le chargement des données
Que ce soit à partir d’une base de données, d’un fichier RDS, de fichiers Excel, ou autres, on a quasiment toujours des données à charger au lancement de l’application.
data <- readRDS("data/data.rds")La définition de variables globales
Les variables globales sont des constantes qui vont être utilisées un peu partout dans l’application. Ici, un exemple où on fixe l’année de production à la main.
production_year <- 2025La définition d’options R
Les options permettent de spécifier la manière dont certains packages vont fonctionner. Ici, on s’évite la notation scientifique des grands nombres, et on paramètre le spinner utilisé par le package shinycssloaders.
options(
scipen = 1000,
spinner.type = 5,
spinner.color.background = "#FFFFFF",
spinner.color = "#2D2264",
)Et c’est à peu près tout, ce fichier doit rester léger.
Pas de définition de fonctions : Elles doivent être définies dans un fichier dédié.
Pas de préparation de données : Si préparation il y a, elle doit être faite avant le démarrage de l’application.
Pourquoi un global ?
Dans une application Shiny, tous les utilisateurs viennent se connecter au même processus R. À la même "session R" si vous préférez.
Ça veut dire que si vous chargez une variable dans l'environnement global, cette variable est disponible pour tous les autres utilisateurs.
Dangereux ? Utile ? Je réponds oui.
Tout ce que vous chargez dans le global.R va être partagé parmi tous les utilisateurs. En terme d'optimisation de la mémoire, ça peut être extrêmement utile.
Mais si vous ne faites pas attention, ça peut aussi être un risque de sécurité, tel qu'un accès à des données qu'un utilisateur ne devrait pas voir.
Heureusement, à l'inverse, tout ce qui est chargé à l'intérieur de la fonction server est spécifique pour la session de l'utilisateur.
En savoir plus : Scoping rules for Shiny apps
Voici un exemple concret du fichier global que j’ai créé lors du Shiny Hackathon :
library(data.table)
library(shiny)
library(ggplot2)
# ------ Global variables ------------------------------------------------------
ref_files <- list.files("data/refs", full.names = TRUE)
ref_list <- lapply(ref_files, data.table::fread)
names(ref_list) <- stringr::str_remove(basename(ref_files), ".csv")
custom_palette <- c(
"#023364", # dark-blue (primary) - anchor the palette with your primary brand color
"#FF7043", # orange - strong contrast to blue for clear category separation
"#80ED99", # green - complementary to the blues and orange
"#B05617", # warning amber - earthy tone that contrasts with previous colors
"#0466C8", # light-blue - return to the brand family but visually distinct
"#B71B1B", # danger red - high contrast
"#FFD4C7", # orange-30 - soft tone for variety
"#1F6F31" # success green - darker than the first green for distinction
)
# ------ Load data -------------------------------------------------------------
data_files <- list.files("data", pattern = "*.csv", full.names = TRUE)
data_list <- lapply(data_files, data.table::fread)
names(data_list) <- stringr::str_remove(basename(data_files), ".csv")On y retrouve :
- Le chargement des packages.
- La définition de variables globales. Ici on vient lire des tables de référence qui sont stockées au format CSV dans le dossier
data/refs/. On définit aussi une palette de couleurs. - Le chargement des données.
Et c’est tout. Cet exemple est assez typique de ce qu’on retrouve sur nos applis habituelles.
Notez aussi l’utilisation des commentaires pour structurer le fichier. C’est une autre de nos règles de syntaxe. Six tirets, un titre, et on complète la ligne jusqu’au maximum des 80 caractères par ligne.
# ------ Global variables ------------------------------------------------------Ces commentaires structurés permettent de créer automatiquement une “Outline” sur votre RStudio ou VSCode.
À présent, passons au fichier ui.R.
Le fichier ui.R
De manière plus simple et classique, le fichier ui.R contient l’interface utilisateur. Généralement, c’est un fichier qui reste assez court et dont l’objectif est d’appeler des modules Shiny.
Voici l’exemple du Shiny Hackathon :
bslib::page_fluid(
title = "Shiny App",
theme = bslib::bs_theme(
version = 5,
primary = "#023364"
),
shinyjs::useShinyjs(),
includeCSS("www/css/main.min.css"),
includeScript("www/js/shiny_custom_message.js"),
fluidRow(
column(
width = 12,
class = "header",
tags$img(
src = "img/logo.png",
alt = "Logo Data Champ’",
width = "50px"
),
h3("FDA Adverse Events Reporting System (FAERS) Public Dashboard")
)
),
home_ui("home")
)Ce fichier utilise des outils modernes comme bslib et shinyjs. Ici on va :
- Charger un fichier CSS et un fichier JavaScript.
- Créer un en-tête.
- Charger un premier module
home_ui("home").
On reste sur une application très simple ici. La modularisation avec home_ui() peut ne pas sembler nécessaire. Mais si on prévoit plus tard d’ajouter d’autres pages, peut-être avec des onglets, on sera content d’avoir des modules.
À nouveau : Pas de définition de fonction, et pas non plus de définition de variables qui auraient plutôt leur place dans le global.R.
Chaque objet à sa place.
Le fichier server.R
Finalement, la partie serveur va permettre de coder toute la logique interactive de l’application.
Ici, on a une simple fonction, qu’il faudra remplir :
function(input, output, session) {
}Tout le code sera défini à l’intérieur de la fonction. Là encore, on pourra appeler des modules pour organiser le code.
Ce fichier a tendance à grossir beaucoup plus facilement que le ui.R. Pour savoir quand un fichier est trop gros, nous avons une règle très simple :
Pas plus de 500 lignes pour un fichier.
Si un fichier fait plus que 500 lignes, il faut le découper.
Voyez l’exemple du Shiny Hackathon :
function(input, output, session) {
# ------ INITIALIZE --------------------------------------------------------
# Initialize session variables
session$userData$disclaimer_accepted <- FALSE
# ------ MODULES -----------------------------------------------------------
# ------ * Disclaimer ------------------------------------------------------
if (Sys.getenv("HIDE_DISCLAIMER") != "true") {
showModal(modalDialog(
title = NULL,
footer = NULL,
easyClose = FALSE,
size = "l",
disclaimer_ui("disclaimer")
))
disclaimer_server("disclaimer")
}
# ------ * Home ------------------------------------------------------------
home_server("home")
}Très simplement :
- On initialise une variable de session
session$userData$disclaimer_accepted - On appelle deux modules.
Fin de l’histoire.
Notez à nouveau l’utilisation des commentaires structurants. Ici on peut voir que j’utilise une certain syntaxe pour représenter la hiérarchie des blocs de code :
- En MAJUSCULES les titres des grandes sections
- Avec une astérisque en préfixe pour les titres des blocs de code
Cette structure se retrouve à nouveau dans l’Outline de l’IDE qui permet de bien identifier la hiérarchie.
On progresse doucement, pour l’instant on a tout juste trois fichiers :
mon-projet-shiny/
├── global.R
├── ui.R
└── server.R
Prochaine étape : Découper en modules Shiny.
3. Modulariser l’application à l’aide des modules Shiny
Peur des modules ?
Ça vous fait peur les modules ?
Ça ne devrait pas.
Les modules sont souvent considérés comme une pratique “avancée” en Shiny, et il n’y rien de plus faux.
Un module est une fonction. On va donc encapsuler dans une fonction du code qui appartiendrait normalement à ui.R ou à server.R, et on va appeler cette fonction.
De la même manière qu’une fonction peut appeler une autre fonction, un module peut appeler d’autres modules.
On peut alors définir toute une hiérarchie qui refèlte la réalité de l’application Shiny.
Voici un exemple d’architecture avec 2 niveaux de modules :
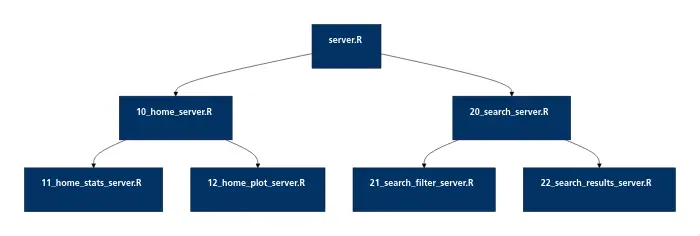
Ci-dessous un autre exemple plus complexe que nous avions réalisé lors de la conception de l’architecture d’une appli :
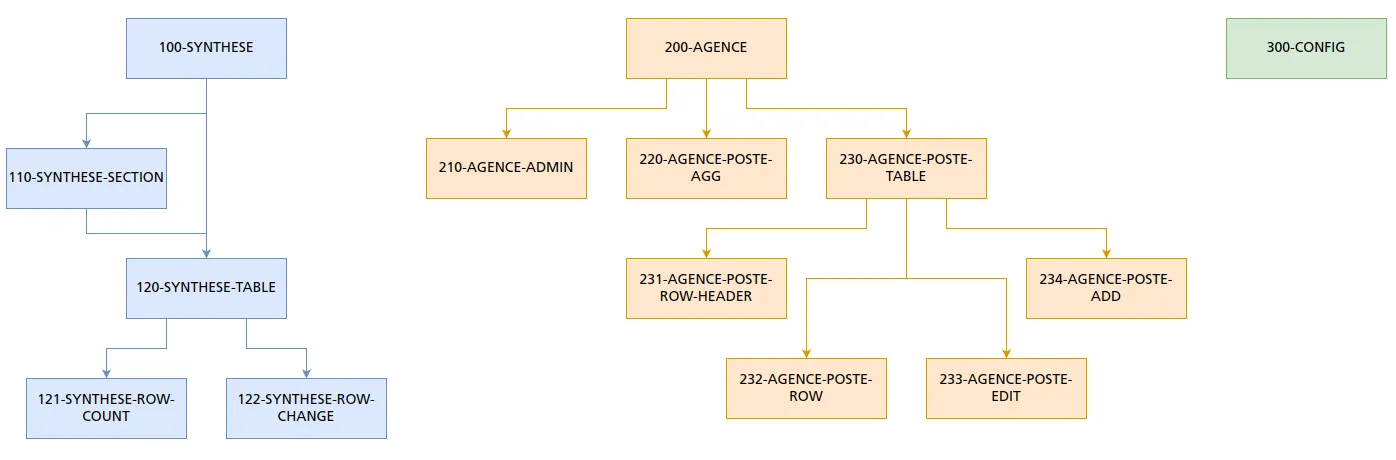
Voilà. Vous en savez suffisamment pour comprendre le reste de cette section.
Et si vraiment vous voulez voir comment ça marche sous le capot, jetez un coup d’œil à cet article : Modularizing Shiny app code.
Vous l’avez compris, les modules sont des fonctions. Ils vont donc être rangés dans le dossier R/.
L’idée ici, c’est de continuer à organiser le code pour éviter d’avoir des fichiers avec plusieurs milliards de lignes de code.
Je répète ma règle simple :
Un fichier ne doit jamais faire plus de 500 lignes de code.
500 c’est même déjà beaucoup.
Si j’arrive à plus que 500 lignes, il y a de fortes chances que mon fichier ne respecte pas le principe de Séparation des Responsabilités, c’est-à-dire qu’il contient des briques de code qui mélangent plusieurs concepts.
En général, c’est l’occasion de découper le fichier en plusieurs morceaux.
Modulariser facilement
Le plus classique, c’est d’avoir un module par écran :
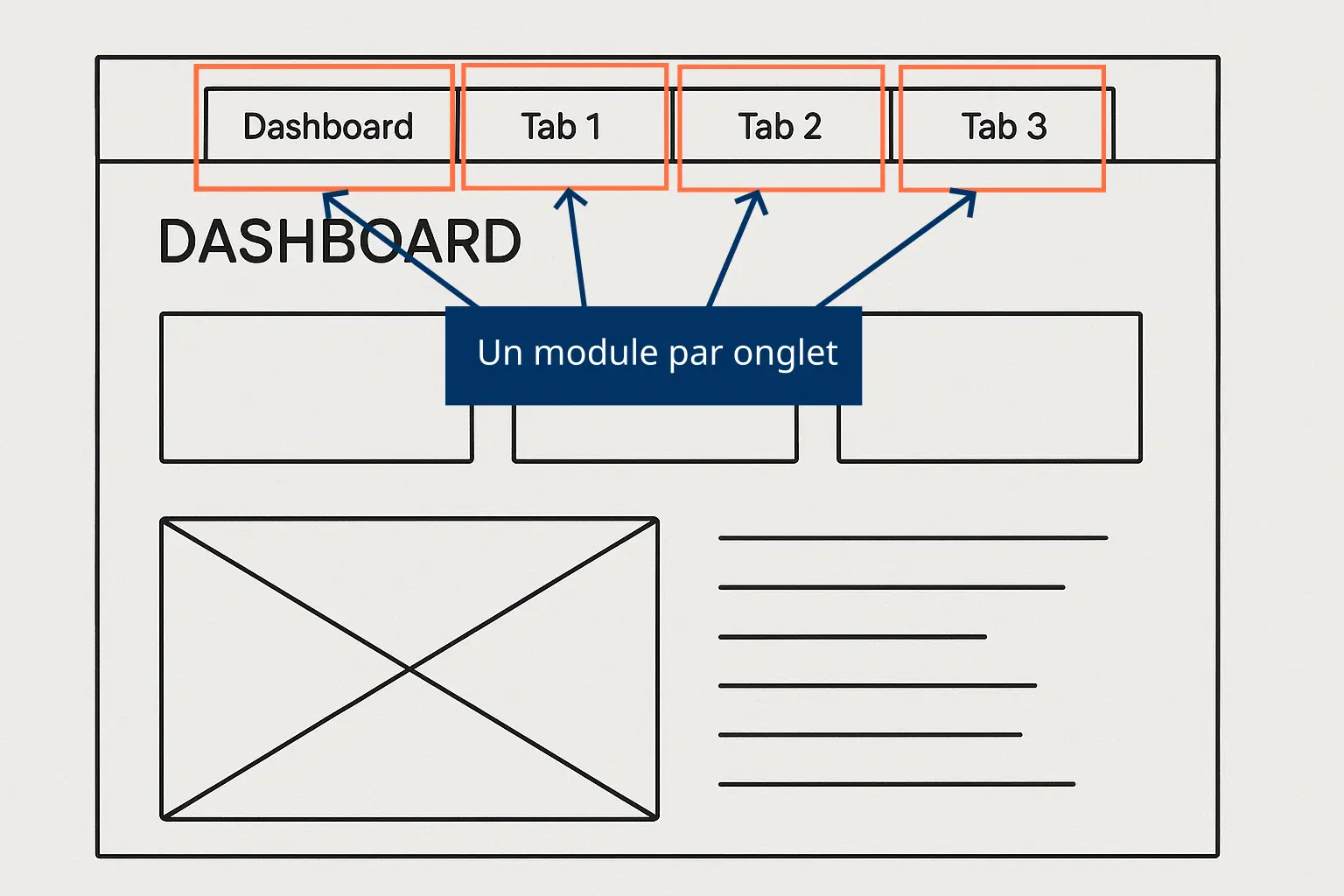
On utilise un bslib::navset_bar() avec un écran par onglet, et on a une répartition logique d’un module par écran.
Parfois, on peut aussi avoir un écran très chargé. Dans ce cas, il faudra plutôt identifier des zones de l’écran qu’on peut modulariser.
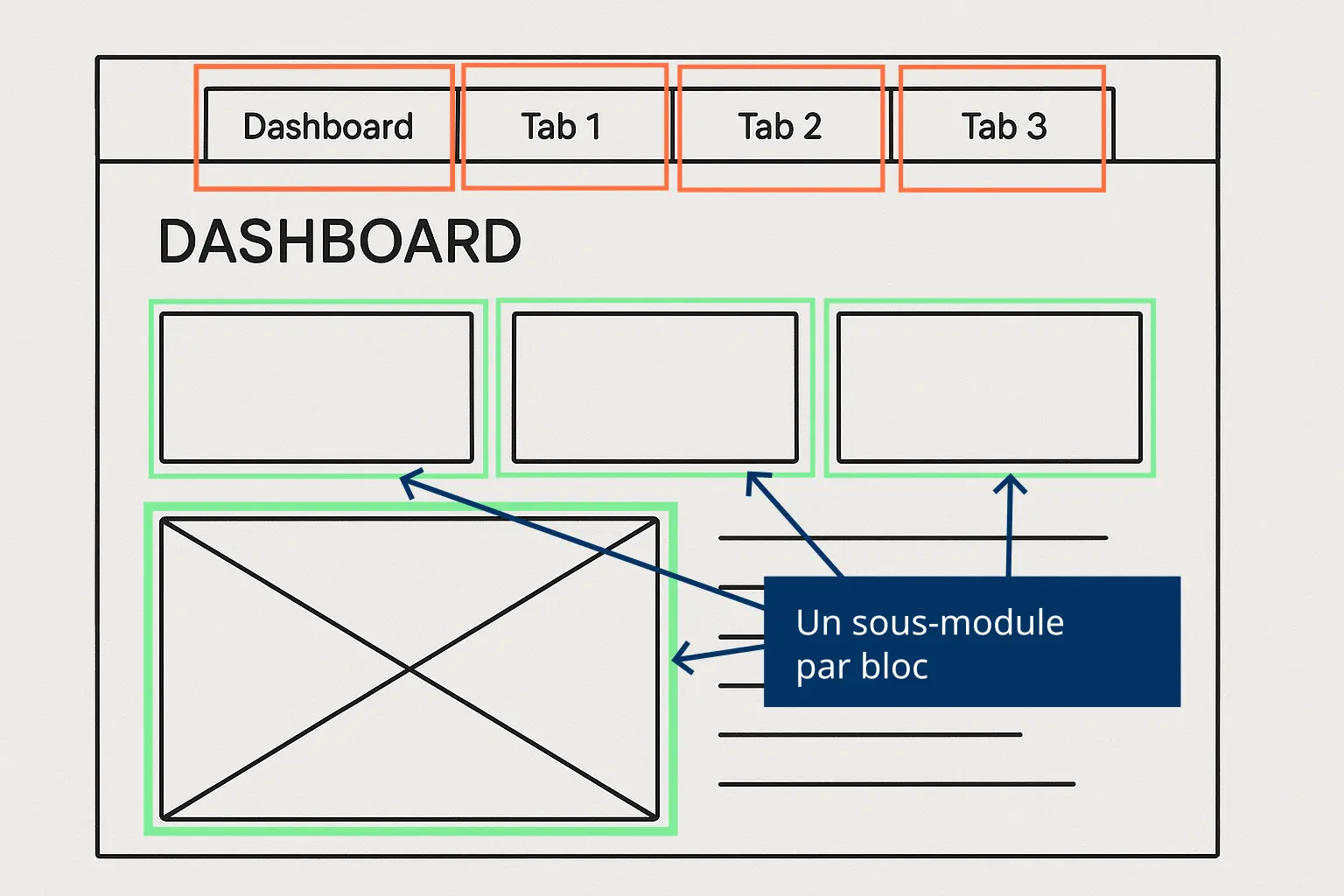
Un module est réparti en trois fichiers :
- Fichier UI : C’est la partie UI du module.
- Fichier Server : C’est la fonction server du module.
- Fichier de fonctions : Ce fichier optionnel contient les fonctions qui sont exclusives à ce module.
Modules - le fichier UI
Voici un template de base du fichier UI :
module_name_ui <- function(id) {
ns <- NS(id)
div(
id = ns("main")
)
}De base, on a besoin d’un argument id et de cet objet ns (pour : namespace). Et ensuite, on remplit l’interface avec tout ce dont on a l’habitude en Shiny.
Pour le nommage du module, la règle est simple : module_name_ui tout en snake_case. Par exemple : home_ui(), search_ui(), disclaimer_ui().
Voici un exemple plus fourni d’un module UI à partir du code du Shiny Hackathon :
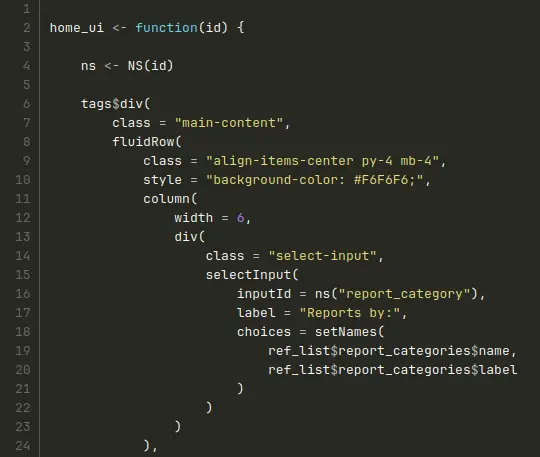
Modules - le fichier Serveur
Côté serveur, le template de base est un poil plus complexe :
module_name_server <- function(
id
) { moduleServer(id, function(input, output, session) {
ns <- session$ns
# ------ REACTIVE ----------------------------------------------------------
# ------ MODULES -----------------------------------------------------------
# ------ OUTPUT ------------------------------------------------------------
return(values)
})}Premièrement, vous serez sans doute un peu surpris par les premières lignes. Pourquoi ne pas écrire plus classiquement :
module_name_server <- function(
id
) {
moduleServer(id, function(input, output, session) {
# blabla
})
}Si vous faites ça, tout votre code est automatiquement indenté deux fois. Je ne sais pas comment ils ont fait leur affaire chez Posit pour arriver à cette syntaxe, mais perso je préférais largement l’écriture d’avant qui était beaucoup plus légère.
Et comme chez nous on utilise 4 espaces par indentation, pour améliorer la lisibilité, et qu’on se limite à 80 caractères par ligne, ça veut dire qu’on se prend systématiquement 8 espaces perdus sur notre écran.
C’est hors de question.
Du coup j’utilise cette écriture un peu surprenante pour se limiter à une seule indentation :
module_name_server <- function(
id
) { moduleServer(id, function(input, output, session) {
# blabla
})}Ensuite, vous aurez noté la préparation des commentaires structurants pour les sections classiques qu’on va retrouver quasiment systématiquement dans les parties serveur des modules.
Et finalement, le nommage de la fonction serveur est en miroir du nommage de la fonction ui : home_server(), search_server(), disclaimer_server().
Voici l’exemple du Shiny Hackathon :
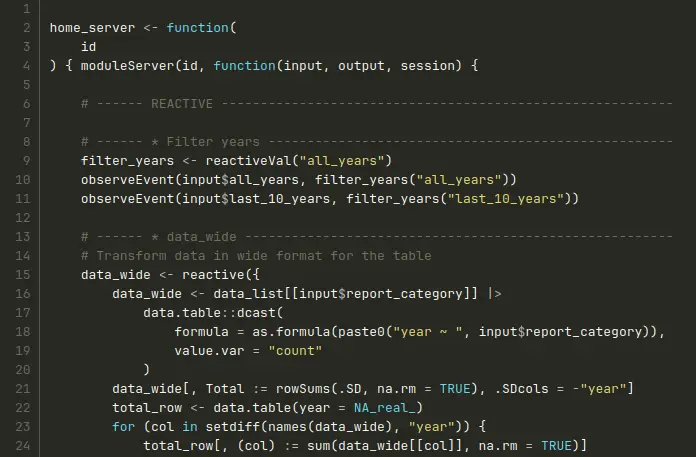
Modules - le fichier de fonctions
Il reste un fichier : Le fichier de fonctions.
Il est optionnel. C’est seulement quand on souhaite définir une fonction dont l’usage va être spécifique pour ce module qu’on l’utilise. Sinon, on stockera la fonction dans un fichier à usage plus généraliste.
Le nommage des fichiers de modules
Je veux aborder un dernier sujet : Le nommage des fichiers.
Il reflète le nommage des fonctions : Pour un module home_ui(), on va appeler le fichier home_ui.R.
Mais on va plus loin : Les modules sont numérotés pour refléter leur ordre d’apparition dans l’application. Très classiquement, on va souvent avoir des onglets. On numérote alors le module selon l’ordre des onglets :
10_home_ui.Rpour le premier onglet20_search_ui.Rpour le deuxième onglet- et ainsi de suite
Et pourquoi 10, 20, et pas juste 1, 2 ?
Parce qu’ensuite, on va considérer les sous-modules. Le module 10_home_ui peut contenir 3 sous-modules :
11_titre_ui.Rpour le titre12_graph_ui.Rpour le graphique13_table_ui.Rpour le tableau
Au début, je n’étais pas fan de numéroter les fichiers. Je me disais que j’allais passer des heures à changer tout le temps les numéros.
En pratique, c’est assez rare, surtout si on a pris un peu le temps de réfléchir à l’architecture de l’application en avance.
Et surtout, je trouve que c’est super utile, parce que ça range automatiquement les fichiers dans un ordre logique par rapport à l’application, ce qui évite de perdre du temps à chercher le fichier dont vous avez besoin.
Encore mieux : Avec VSCode, j’utilise le raccourci Ctrl + P pour chercher un fichier, je tape juste le numéro et j’ouvre le fichier en seulement 2-3 secondes.

Vous l’aviez peut-être remarqué, les deux présentations d’architectures modulaires ci-dessus utilisaient ce nommage avec numérotation :
Et on fait quoi si on a plus que 9 sous-modules ?
Euh… Là je ne sais pas, ça m’est jamais arrivé.
Regardons plutôt notre structure de projet qui se complète :
mon-projet-shiny/
├── R/
├── 100_home_server.R
├── 100_home_ui.R
├── 200_search_server.R
└── 200_search_ui.R
├── 300_disclaimer_server.R
└── 300_disclaimer_ui.R
├── global.R
├── server.R
└── ui.R
4. Structuration du reste des fichiers
Quid du reste des fichiers ? Selon les projets, l’arborescence peut devenir très riche.
Les données
Si l’application utilise des données sous la forme de fichiers (CSV, Excel, RDS, etc.), ces données sont stockées dans un dossier data/.
Attention : En général, on évite de versionner les données sous Git.
Attention 2 : Évitez de stocker des données à l’intérieur du dossier www/. Celui-ci est servi par le serveur Shiny, ce qui veut dire que les fichiers qu’il contient sont accessibles depuis l’internet. Pas sûr que vous ayez envie que tout le monde accède directement aux données sources.
Pour le Shiny Hackathon, j’avais préparé quelques fichiers CSV, et une table de référence. J’ai tout stocké dans un dossier data/ puis un sous-dossier data/refs/ :
data/
├── refs/
├── report_categories.csv
├── age_group.csv
├── report_type.csv
├── reporter.csv
├── reporter_region.csv
├── seriousness.csv
└── sex.csv
La préparation des données
Dans certaines applications, les données évoluent régulièrement et doivent être pré-traitées avant d’être exploitables par l’application.
Règle simple : On évite le plus possible de faire des traitements de données au sein de l’application Shiny. Ça ne sert à rien, à part créer des lenteurs.
À la place, on va préférer faire ces traitements en dehors de l’utilisation de l’application. Les scripts de préparations de données sont stockés dans le dossier data_prep/.
Puis un planificateur de tâches (de type cron) va faire tourner ces scripts à la fréquence souhaitée.
Le renv
Nous utilisons renv pour gérer les packages R et assurer la reproductibilité du projet sur tous nos environnements.
L’idée ici n’est pas de faire un cours sur renv, d’autant que ce sera détaillé dans les prochaines parties de la série d’articles. D’ici là, vous pouvez jeter un coup d’œil sur la documentation officielle : Introduction to renv
renv crée plusieurs fichiers et dossiers :
- Le dossier
renv/qui va contenir les packages installés - Le fichier compagnon
renv.lock - Et le fichier
.Rprofiles’il n’existe pas déjà et qui va permettre de charger le renv automatiquement.
Le dossier de ressources www/
Le dossier www/ contient tous les fichiers nécessaires à l’application qui ne sont pas des scripts R. On y trouve principalement :
www/css/pour les fichiers CSSwww/html/pour les templates HTMLwww/img/pour les imageswww/js/pour les scripts JavaScriptwww/sass/pour les scripts SASS si vous utilisez le packagesass
Vous n’êtes pas obligés de stocker tous ces fichiers dans le dossier www/. C’est ce qui est prévu nativement par Shiny, et c’est pourquoi ces fichiers seront automatiquement accessibles.
Si vous décidez d’utiliser plutôt xxx, sachez que vous devrez alors déclarer le dossier à Shiny pour que les ressources soient disponibles, en utilisant la fonction shiny::addResourcePath().
Pour aller plus loin : Organiser vos fichiers CSS
J’aime bien utiliser SASS pour écrire tout le code CSS. SASS est en fait un pré-compilateur de code CSS qui va nous donner des outils supplémentaires : variables, fonctions, boucles, etc.
Plus d’infos sur le site de libSass et le site du package R de sass.
Là encore, les applis qu’on nous envoie ont généralement un seul fichier style.css qui peut faire des milliers de lignes avec tout le CSS de l’appli.
Super.
Voici comment on fonctionne.
D’abord, on découpe notre CSS en quatre sections :
- Le CSS de base : On définit les couleurs principales, les typographies, la taille des texte, etc. La base.
- Les composants : On définit un fichier par composant. Un composant ça peut être un tableau, un
selectInput, c’est un élément simple de l’application. - Le layout : C’est ce qui constitue le squelette structurant de l’application. Le header, le footer, les onglets, etc.
- Les pages : Tout le CSS relatif à certaines pages en particulier et qui ne se généralise pas à l’application toute entière.
Chaque section va être l’objet d’un sous-dossier dans www/sass, et chaque sous-dossier peut contenir plusieurs fichiers. Par exemple, le dossier www/sass/components va contenir un fichier par composant.
Ensuite, le fichier www/sass/main.scss va agréger tous ces fichiers ensemble. Voici l’exemple du Shiny Hackathon :
// Base
@import "base/variables";
// Components
@import "components/grid-table";
@import "components/select-input";
@import "components/value-box";
@import "components/checkbox";
// Layout
@import "layout/body";
@import "layout/footer";
@import "layout/header";
@import "layout/modal";Pour terminer, on crée un fichier R/sass.R qui est toujours le même dans tous nos projets :
sass::sass(
input = list(
sass::sass_file("www/sass/main.scss")
),
output = "www/css/main.min.css",
options = sass::sass_options(output_style = "compressed")
)Tout le code SASS est pré-compilé pour donner un fichier compressé en CSS : www/css/main.min.css, qu’on va venir charger dans le ui.R avec : includeCSS("www/css/main.min.css").
Là on a fait une petite digression sur un sujet un peu avancé. Si vous souhaitez en savoir plus, je vous invite à étudier le code du Shiny Hackathon directement.
Les fichiers à la racine du projet
On retrouve ensuite tout un ensemble de fichiers qui traînent à la racine, en nombre limité.
.gitignoreutilisé par Git pour spécifier les fichiers à ne pas versioner.gitlab-ci.ymlutilisé par Gitlab pour définir les pipelines CI/CD.lintrutilisé par le packagelintrqui permet de vérifier la qualité du code.Renvironpour définir les variables d’environnementREADME.mdpour décrire une documentation générale du projet
Chacun de ces fichiers a une importance cruciale. Les prochains articles développerons leur utilisation.
Les fichiers de tests
Finalement, un dossier tests/ va regrouper l’ensemble des tests liés au projet.
À l’intérieur du dossier tests/, on va trouver le fichier tests/testthat.R. Celui-ci est en général très court puisqu’il contient la ou les fonctions nécessaires pour lancer l’ensemble des tests. Par exemple :
shinytest2::test_app()Ici, on va lancer tous les tests de bout en bout à l’aide du package shinytest2.
Ensuite, les fichiers contenant les vrais tests sont dans un sous-dossier tests/testthat.
Structure finale du projet
Et là, ça y est, on a tout. Voici à quoi ressemble la structure de quasiment tous nos projets Shiny :
mon-projet-shiny/
├── data/
├── refs/
├── report_categories.csv
├── age_group.csv
├── report_type.csv
├── reporter.csv
├── reporter_region.csv
├── seriousness.csv
└── sex.csv
├── data_prep/
├── data_prep.R
├── R/
├── 100_home_server.R
├── 100_home_ui.R
├── 200_search_server.R
└── 200_search_ui.R
├── 300_disclaimer_server.R
└── 300_disclaimer_ui.R
├── renv/
├── tests/
├── testthat.R
└── testthat/
├── .gitignore
├── .Renviron
├── global.R
├── README.md
├── renv.lock
├── server.R
└── ui.R
Vous avez à présent une vue d’ensemble sur la manière de structurer proprement une application Shiny :
- Les trois fichiers fondamentaux à la racine (
global.R,ui.R,server.R) - Un découpage par module (c’est fini les monstres de 39 000 lignes)
- Une structure de dossiers cohérente qui donne sa place à chaque fichier
- Des règles simples : Pas plus de 500 lignes par fichier.
Cette méthodologie est faite pour être simple, ne pas créer de contraintes superflues, et créer des applications faciles à maintenir.
Et ce n’est que la première étape.
Dans les prochains articles, on va parler de gestion d’environnement, de qualité de code, et de collaboration entre plusieurs développeurs.
Commentaires